In software development, we are always releasing new features as quickly as possible. But a feature is only complete once it is operating as intended without requiring excessive escalations or unanticipated work. DevOps helps to optimise the speed of delivering a feature while making sure that it remains of good quality and does not require significant rework.
Here is how we use DevOps at Nmbrs to deliver new features, bug corrections, and improvements faster.

Why we use DevOps at Nmbrs
In my previous article, I covered some of the key concepts of DevOps, including lean operations to reduce the technology value stream and the principles of continual learning and experimentation.
Here I will focus on where to start implementing DevOps principles and some technical practices in the development operations flow. While this article could be read on its own, I would recommend reading the previous article to learn more about the theory of DevOps first.
Before moving on, let me briefly introduce you to who I am and why Nmbrs uses DevOps. I’m a Full Stack Software Engineer and currently work at Nmbrs, an international HR & Payroll software company. At Nmbrs, we are always looking to improve the technology value stream through DevOps, and although we are still perfecting the way we do things, we have seen a lot of benefits from implementing DevOps into the way we do things, including:
- Faster releases of new features, fewer bugs, more security, improved performance, maintenance, etc.
- A better quality product and way less rework to be done after we release new features.
- Improved developer independence. Each person is accountable for their tasks and has the autonomy to release them without requiring approval from others.
Using organisational archetypes to see if you can easily implement DevOps
Before we look at how to implement DevOps, we need to understand what kind of organisation best suits this set of practices. Here are three of the main types of organisational archetypes:
- Functional-Oriented Organisations: the main purpose of this style of organisation is to save costs by optimising for expertise and experience. They typically have vertical structures, where each department is a specialised unit, and the workers are organised based on their specific skills and knowledge.
- Market-Oriented Organisations: the main purpose of this style of organisation is to quickly respond to customer needs by optimising for customers' responses. They are typically flat, with multiple and cross-functional disciplines. Nmbrs is a market-oriented organisation. In general, each developer is a Full Stack Engineer.
- Matrix-Oriented Organisation: attempt to combine functional and market orientation.
Best practices in DevOps emphasise optimising for speed over optimising for cost to improve the ability of small teams to deliver customer value quickly. This is best achieved with cross-functional and self-sufficient teams that can quickly become proficient in feature development. As speed is the key, an organisation that is market-oriented is best positioned to implement DevOps and benefit from it.
While matrix-orientated organisations that contain a level of cross-functional work can easily implement DevOps, in general, functional-oriented and matrix-orientated organisations find it more difficult to implement these sets of practices that are designed for speed. In these cases, it might be better to consider restructuring if you want to incorporate DevOps into your organisation.
After recognising where our organisation is and feeling prepared to embrace a new era, we can start implementing DevOps. Luckily for us at Nmbrs, we were already operating as a market-orientated organisation, so we could get started on implementing DevOps with ease.
Next, I will discuss some of the ways that DevOps can be implemented with speed in mind and how we at Nmbrs have been implementing these aspects.
Improve testing strategies for better feature development
One of the key principles of DevOps is to improve the way that we test new features and updates. By effectively testing throughout the development process, we are able to decrease the amount of rework, increase work quality, and raise customer satisfaction. Here is how we can improve testing through DevOps.
Work in production-like environments
Testing in production-like environments from the earliest stages of a software project allows us to considerably reduce the chance of subsequent production problems. We can do this by working in testing environments that are as close to the production environment as possible. In other words, they should be 'copies' of production.
However, we still want to keep the testing and production builds separate and have distinct test processes. This will guarantee that we understand all the dependencies required to create, package, run, and test our code. In other words, eliminating the "it worked on my machine, but it broke in production" issue.
Even newcomers find it simpler. The authors of The DevOps Handbook showed that new team members were able to make productive contributions to this complex system quickly, thanks to good test coverage and code health.
Write automated tests
When a new update is introduced into version control, we require rapid automated tests that run within our build and test environments. This ensures that if something breaks, it's picked up immediately, and the developer can fix it, even before moving on to the next task. As a result, there will be fewer code reds down the line, and the transition between the developer and the tester will be smoother.
In general, automated tests are classified as one of the following, in order of processing time:
- Unit tests are the fastest level of testing as they check smaller components of larger projects, such as single methods, functions, or classes, in isolation.
- Integration tests are more time-consuming to maintain as they help guarantee our application interacts correctly with other production apps. They have significantly more system touchpoints than unit tests and thus change more frequently.
- Acceptance tests are the slowest version of testing, as they typically test the entire application to see if it's functioning properly. While acceptance tests are usually done after the deployment of a release, we can benefit more from them if we run them during the earliest stages of a feature release.
Whenever an error is discovered during an acceptance or integration test, we should write a unit test to find the error faster, earlier, and cheaper. The new unit test means that any potential errors will be detected earlier the next time we do an update.
At Nmbrs, we have technical debt regarding automated tests. In other words, the number of tests we have currently implemented covers just a small slice of the whole pie. This means that we need to create and implement more automated tests to cover every aspect.
The problem is that retroactively implementing tests is difficult due to a lack of time and knowledge - it would have been better if we first created unit tests, even before developing new features, as this would have saved us a lot of time and effort.
However, since we have started utilising the principles of DevOps and built improved automated testing into our development process, we have seen a huge improvement in the speed at which we pick up errors and fix them.
While we still have a long way to go in terms of catching up with our technical debt, we are overcoming this issue by having end-to-end tests maintained by our Quality Assurance Engineers.
Release management: setting a clear process from development to release
Release management in a DevOps setting refers to the planning and deployment of software in production environments. The purpose of release management is to ensure that new features, bug fixes, and maintenance reach customers in a reliable and efficient way.
If you try to integrate every deployment and release manually, it will be a tedious and repetitive process. In DevOps, we must automate as much as possible to reduce the technology value stream. That is why we at Nmbrs have automatic and well-documented builds and releases.
Automating builds for efficient feature deployment
At Nmbrs, each automatic build has a unique build number, which identifies what’s in that build. This helps create traceability for our deployments and makes life easier when choosing the build number we will use when releasing a set of features.
Each build number is indirectly associated with a fix version. You can have multiple _build numbers inside a fix version, which is how we keep track of each release. _This way, if something goes wrong during or after a new deployment, we can identify which version we need to roll back.
This is our process from the beginning of development until the release:
- Whenever a task is ready to be tested/validated, the developer merges the code into a development branch.
a. In the background, in Azure, a pipeline is triggered and will automatically create a new build version.
b. Next, it will trigger an automatic deployment to what we call our kitchen environment (the developer's playground).
c. Finally, when it’s available, the developer must ask another person to test the task. - If it passes the testing phase, the developer needs to merge his code into the test branch. This will trigger the same actions as before but point them to the test. Once this is done, the developer should ask QA to test the task again.
- If all the tests are green, then the developer can finally plan to release the task. Whenever he deploys a new version to production, we have a background task that will increase the fix version number by one.
By following this process, we are able to automate all the triggers and make sure our new feature is rapidly and thoroughly tested before release. Whenever a developer merges new code into version control, we will automatically continue the process. This helps further reduce the technology value stream.
Note: You can release only certain features to a segment of customers by creating a feature flag or by whitelisting certain clients in your deployment.
Automating releases for faster feature delivery
There are multiple approaches to automating the release process. I will show you two different cases. The first case is what we do at Nmbrs. In terms of DevOps, this might not be the ideal way to release with speed. That is why, in the second case, I will discuss the ideal deployment pattern that we are attempting to move towards.
Typical Automated Release
At Nmbrs, we have a monolithic application and a microservice - both of which are deployed and released.
The monolithic application is an aggregation of projects. This application is built as a single unit, and inside it, we currently have 53 projects. Every week we do a release for the monolith. As we only have one web application, we need to stop it, deploy it, release the artefacts, and restart the application. This takes almost two hours and causes downtime for the entire period. This means that our clients can't work with our application for two hours. This is a problem because if a person wants to use the application, they can’t. The client will feel frustrated.
The microservice, on the other hand, is a collection of smaller projects, with each project independently deployable. This means that whenever it is necessary, we can release it - we don't have to make a plan for this. It also only causes five minutes of downtime for the client. Plus, during this time, the clients can still use the main product - only the features related to that microservice won't be available.
The deployment time difference is 96% - making the deployment of the microservices much more efficient and more in line with DevOps.
In order to improve our technology value stream and reduce release times, we are working on improving our automated release system. This leads me to blue-green deployment.
Blue-green deployment
The ideal solution is to not cause any downtime for customers when releasing new features or updates. By 2015, Amazon was performing nearly 136.000 deployments per day. Did you ever notice any downtime in their application? Probably not. This is because they use a variation of the blue-green pattern of deployment.
The blue-green pattern is simple. During the deployment, you create a copy of the web application with all the necessary code and infrastructure. You can then make changes, implement updates, and introduce new features to this copy. When you're ready for release, you route all the users to the new version of the web application - essentially replacing the old version with the new one. This last step releases the new features to all users without them even noticing. This approach won’t cause any downtime, which means happier clients.
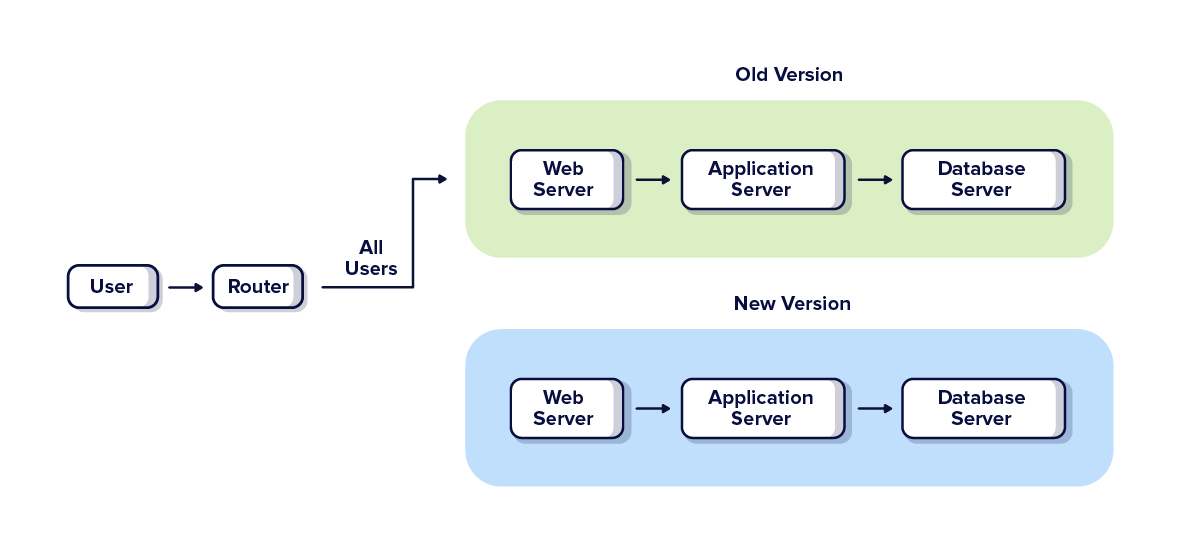
In the most recent Nmbrs project, we implemented this deployment pattern. Here is how we did it:
Our web application is inside a container. Whenever we need to release something, we just create a new container and swap the old version with the new one. The downtime is 0 seconds.
The next step will be to replicate this process on the microservices. For now, using it in the monolithic application is not possible since it has several dependencies on different projects, but we are working towards making this possible.
Conclusion
By improving how we run tests, having clear processes for deployment and release, and automating releases, we are able to deliver new features and updates with fewer bugs to our clients at a much faster pace.
However, as you can see from this article, we can always improve the way we do things to be more in line with the principles of DevOps. If you're keen on finding the best ways to implement these principles in your organisation, then it's important to keep alert to the latest developments in the continually evolving world of DevOps.
Guilherme Pinheiro is an energetic and enthusiastic engineer. He is a Full Stack Engineer and Scrum Master at Nmbrs. Outside of his professional life, he is a sports lover.
Read More
- Lessons on using DevOps to become more efficient and reliable
- Adrian Moisey, Salesloft: How DevOpsDays Sets up Value
- What to Consider when Building a DevSecOps Pipeline
- DevOps Engineer Salary Trends in Germany
- DevOps Engineer Salary Trends in South Africa
