Before Jeremy Edberg founded his own company, MinOps, an SQL interface for the Cloud, he worked at Netflix as its founding reliability engineer. At that time, there was no alerting system to let his team know when things broke, which meant that humans had to monitor the system 24/7. In order to focus more energy on building new features, and spend less time sitting and watching screens, Jeremy and his team set up an automated alerting system. Here, he talks through the features they built into the alerts, and the impact this had on his team.
Watch the full-length studio interview at the end of the post!

Jeremy has had quite an expansive career, having worked at Ebay/PayPal, as the Lead Technologist at Reddit, and as the founding Reliability Engineer at Netflix, before founding his own company. Having worked at different companies in different roles, Jeremy has spent a lot of time building new processes for tech teams. However, one that really stands out for him was the alerting system at Netflix that he helped set up from scratch.
While working as the reliability engineer at Netflix, the company was still predominantly sending DVDs through the post, and online streaming was only just beginning to gain traction. Part of Jeremy’s role included working with the recently established monitoring team to make sure that any website issues were identified quickly, and fixed. As a team, they focused mainly on improving customer experience and driving the business metric of ‘play-starts’: the number of people who clicked play and had the video actually play successfully.
However, this was a lot harder than it might seem because they had no alerting system to tell them when the site was down: “The only way we would know is when people would call customer service, and complain that they couldn't stream,” Jeremy explains. “That was the entirety of the alerting system at the time”. His team also had no way of diagnosing where the problem was, and had no way of contacting the person responsible for fixing it.
This meant that his team was constrained in the following ways:
- Development was slower: Someone had to find out that something was broken, find out who to call, and then call that person and let them know what needed fixing. Each part of the system that needed a human being made the process slower: “Any time you involve a human, reliability is immediately going to drop an order of magnitude, just based on human response times”.
- People had to be on call outside of normal working hours: Peak traffic at Netflix tended to be outside of working hours. As a result, developers needed to be on call overnight and over the weekend. Hiring more people just to monitor those hours was made even harder because Netflix only hires senior developers as a rule and, often, these developers didn't want to work on Saturday nights. He says, “We wanted to get to a place where we didn't have to hire people to sit and watch monitors on weekends and holidays”.
- His team needed to maintain ‘three nines’: In order to keep Netflix’s system at 99.9% (or ‘three nines’), he could not afford slow development or slow fixes. “Even just a few seconds of downtime on the site affected the ‘number of nines’,” Jeremy explains, “which meant that we really had to do a lot more automation in general”.
The solution to these constraints was an automated alerting system built by the monitoring team that didn’t rely on humans fixing problems. The ultimate goal was to build a system that the team could trust: “That was the idea: Get everybody to have enough faith in the alert system that they felt comfortable not watching it all the time. Not just the developers, but the executives too. We had to prove that this system is strong enough that we don't need anybody to watch it.”
To make it really effective, and as reliable as possible, the team implemented the following features into the alerting system:
- Self-service alert set up and silencing
- Automatic system isolation and remediation
- Chaos Engineering separation
- Out-of-band alerting system
Self-service alert set up and silencing
If an alert triggered for every single issue on the site, the noise might mean that really important alerts got lost in the noise. In order to reduce this risk, and align with Netflix’s value that developers have the freedom and responsibility to build, manage and maintain their own code, it was crucial that each engineer could set up their own alerts, and silence them, when they needed to:
“We created a system where any developer could put metrics into the metric system, and create an alert on any metric or any combination of metrics. That was super powerful, because some developers would want to monitor their downstream services, or their upstream services, and get alerts on those. If we were running a big test, like shutting down a whole region or something, that would fire a ton of alerts and you could temporarily silence them.”
This gave the team more freedom, and enabled them to work in ways that were most effective for them.
In case an engineer set up an alert for other people, engineers could also mark whether alerts were useful or not. A button was added to each alert, and Jeremy’s team could track over time which alerts were more useful than others. He says, “The person who received the alert could say ‘yes’ or ‘no’, or ignore it, and then we could give stats over time”. This helped the alert recipient learn which alerts should be kept turned on, or turned off.
Automatic system isolation and remediation
In order to minimise the likelihood of users noticing that the site was broken, bulkheading and automatic fallbacks were used to separate different parts of the system: “There would be an outage, the team would get an alert, it would get resolved, and we'd never even know until after the fact. The main system didn't break because it just sort of sectioned those outages off”.
As an example, if there was an issue with Netflix’s personalised recommendations, the interface would switch to its default recommendations until the outage was resolved. “As a user, you wouldn’t even really know that it happened,” Jeremy explains, “other than maybe looking at it and being like, ‘Netflix is usually better than this’”.
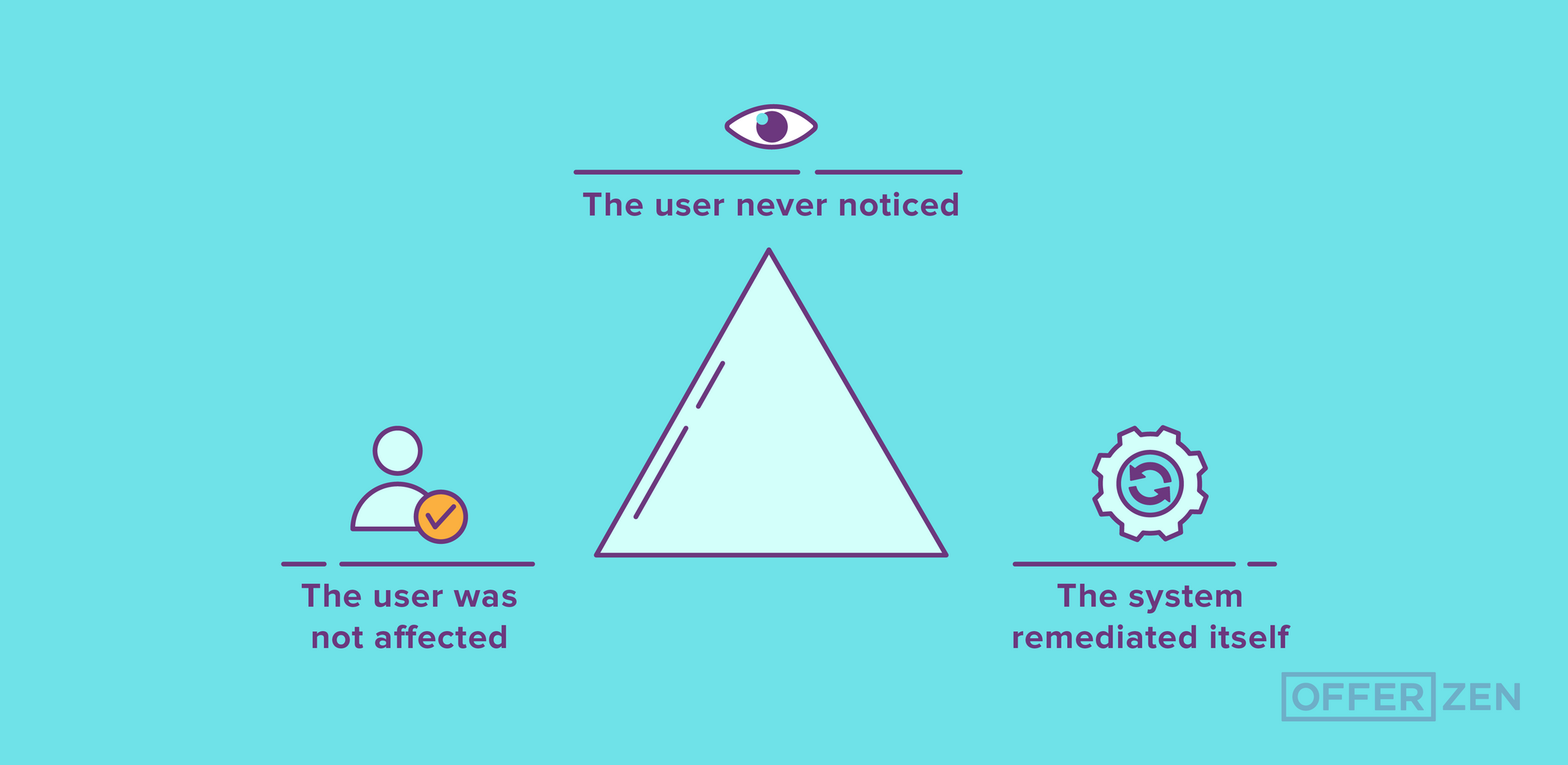
This feature was important because it aligned his team with their ‘customer experience-first’ approach by minimising the number of users who noticed that something was broken on the website. Jeremy describes this by using the image of an ‘ideal outages pyramid’: The user never noticed, the user was not affected and the system remediated itself. Automation helped push more of Netflix’s outages to the ‘users don’t notice’ part of Jeremy’s pyramid.
Chaos Engineering separation
The Chaos Engineering system at Netflix is divided into various roles, defined by using the imagery of ‘monkeys’. The four relevant to this automation include:
- Chaos Monkey: Kills random instances
- Chaos Gorilla: Kills entire zones
- Chaos Kong: Kills entire regions
- Latency Monkey: Degrades network and injects faults
These ‘monkeys’ are essentially built to automatically and deliberately break things in order to bring weaknesses in the system to the surface. The Chaos Monkey runs all the time, and the others are turned on periodically.
In line with another tenet at Netflix, that is to expect failure, Jeremy said that the automated alert system was deliberately built separately to their chaos engineering so that it would pick up the ‘monkeys’ as real alerts:
“We specifically did not tie those systems together, because when we were introducing these failures, we still wanted them to send alerts. If you have not built your system to handle the loss of a server, you should get an alert for that.”
For example, if Jeremy’s team was running a latency test using the Latency Monkey, it was important for engineers to get alerts when the system ran slowly due to errors and outages. “The ideal case,” Jeremy explains, “was that you built your system in such a way that the loss of a single server had no effect. The Chaos Monkey would run, it would destroy a server, it would get replaced, and you'd never even know.”
Out-of-band alerting system
Finally, if the alerting system failed, there needed to be a system that created an alert for the alerting system! This automated ‘meta -alert’ was an out-of-band alerting system that simply enabled Jeremy’s team to put all of their trust into the alerting system.
The benefits of an automated alerts system
The overall impact of the alerting system, and its features, meant that Jeremy’s team was no longer constrained and could:
- Move faster: Because the team could now trust that things would work, and that if they didn’t, alerts would pop up. They also wouldn’t have to spend as much time monitoring their code, which meant that failures were automatically directed to the correct engineer, and fixes were quick and virtually seamless.
- Focus on hiring engineers to build new features: Instead of having to hire people to monitor the system, Jeremy’s team could focus on hiring skills to grow real innovation and generate greater business value. “This alert system let us scale the business faster than we had to ‘scale the engineers’ - or the engineering team - who built it,” he explains. “We didn't have to hire a bunch of people to just sit and watch metrics, and fix things”, which meant Jeremy’s team could focus on rather hiring people to build new things.
- Have increased freedom and more responsibility: By putting an alert system in place, Jeremy’s team had more freedom to build new things, and, therefore, more responsibility for managing the alerts they set up for the code behind those things breaking, if it ever did.
All of this amounts to one key idea, namely: Automate as much as possible, so that your teams work faster and with fewer barriers to success.
“A lot of the chaos testing was around this idea: Break things in production and create systems that automatically remediate, or just aren't affected by those types of outages. The goal was to get to a position where as much as possible was automated so that we would not have to have a human in the loop – because, as soon as you put a human in the loop, it slows things down.”
The automated alerting system not only gave Jeremy’s team more time to work on new features, but it helped reduce how many outages customers experienced on Netflix’s website. Automation ultimately means that developers have more freedom to go home during peak traffic hours, and build innovative code during normal work hours, because they know that if the system breaks, it’ll be automatically remediated or repaired.
